2024.02.21 - [Computer Science/DataBase] - [DB] Key의 종류
[DB] Key의 종류
2024.02.20 - [Computer Science/DataBase] - [DB] 데이터 모델과 용어정리 [DB] 데이터 모델과 용어정리 2024.02.19 - [Computer Science/DataBase] - [DB] DataBase와 SQL VS. NoSQL [DB] DataBase와 SQL VS. NoSQL # DataBase 먼저, 데이터베
blaj2938.tistory.com
DB의 키 종류를 저번 포스팅에 알아보았는데 데이터의 관계를 할때 외래키를 사용하는 것을 알았다. 테이블을 여러개 구성하고 기본키를 참조하여 외래키를 구성한다.
그러면 여기서 궁금한 사항이 있을거다
뭐하러 관계를 맵핑하지? 왜 외뢔키를 써야하지? 걍 하나에 다 때려넣으면 안되려나?라는 생각이든다.
된다. 해도 된다. 상관없다. 하지만 이를 이상(Anomaly)라고 부르기로 했다. 그리고 Anomaly는 3가지로 나뉜다.
# Anomaly
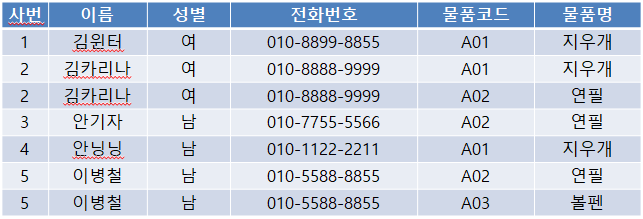
- Insertion Anomaly
- 내가 "장원영"이라는 사원을 추가하고 싶다고 생각해보자. 근데 장원영은 물품을 요청하지 않겠다고 했다. 그럴 경우에 물품코드, 물품명에 Null 값이 들어가게 된다.
- 이를 삽입이상으로한다 ➡️자료삽입할때 의도하지 않은 자료까지 삽입해야만 자료를 테이블에 추가가 가능한 현상
- Modification Anomaly
- 물품코드가 A01인 김카리나가 전화번호를 수정한다고 요청했다. 그러면 2번째 튜플만 수정이 될것이다.
- "김카리나" 동일 인물임에도 2번째 튜플만 수정되어 갱신이상이 발생한다. ➡️ 중복된 데이터 중 일부만 수정되어 데이터 모순이 일어나는 현상
- Deletion Anomaly
- A02번만 삭제하게 되면 김카리나, 이병철, 안기자까지 다 삭제된다.
- 이를 삭제이상이 발생한다. ➡️ 어떤 정보를 삭제하면, 의도치 않은 다른 정보까지 삭제되어버리는 현상
테이블에 이렇게 한번에 모든 정보를 넣게되면 Anomaly가 발생한다. 정규화는 이를 해결할 수 있다.
# Normalization(정규화)
정규화를 알아보기전 Anomaly에 대해서 알아보았다. Anomaly는 3가지로 구성되어있고 삽입, 삭제, 갱신 이상이 있다. 이상의 나만의 정의는 이렇다 할 수 있다. 의도치 않거나, 데이터 모순이 일어나는 현상이라고 정의하겠다.
그렇다면 이런 Anomaly를 해소하기 위해서 Normalization(정규화)을 사용해야한다. 물론, 이상을 방지하는 목적도 있지만 더 큰 목적은 데이터베이스 설계시 중복을 최소화하게 데이터를 구조화 하는 것을 의미한다.
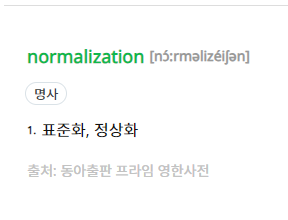
사전적 의미는 표준화, 정상화를 의미한다. 데이터베이스의 Normalization은 한국어뜻에서 표준화에 가깝다고 생각한다. 데이터의 이상을 방지하고 데이터의 관계로 데이터베이스를 잘 조직하는것이 가장 큰 목적이다.
에드거 F.커드는 IBM에서 근무를 하면서 관계형 DB를 만들어냈고 관계형 DB이론에 공헌자이자 제1 정규화 이론을 구축했다. IBM에서 말하는 정규화의 목적에 대해서 알아보자.
| Normalization should be considered when designing Db2® for i database tables and schemas. Several available design methods allow you to design technically correct databases, and effective relational database structure. Some of these methods are based on a design approach called normalization. Normalization refers to the reduction or elimination of storing redundant data.
The primary objective of normalization is to avoid problems that are associated with updating redundant data. 정규화는 i 데이터베이스 테이블과 스키마를 위한 Db2를 설계하는 과정에서 고민되었다. 몇몇 유용한 디자인 메소드들은 정확한 데이터베이스와 효율적인 관계형데이트베이스 구조 설계할 수 있게 했다. 이 방법들은 몇가지는 정규화라고 불리는 설계 접근 방식에 기반이된다. 정규화는 중복된 데이터를 저장하는 것을 줄이거나 제거하는것을 말한다. 정규화의 주된 목적은 중복된 데이터를 업데이트와 관련된 문제를 피하는것이다. |
https://www.ibm.com/docs/en/i/7.5?topic=design-normalization
Normalization
Normalization should be considered when designing Db2® for i database tables and schemas. Several available design methods allow you to design technically correct databases, and effective relational database structure. Some of these methods are based on a
www.ibm.com
결국 다시 목적을 정리하자면 정규화의 정의는 중복된 데이터를 저장하는것을 줄이거나 제거하는것, 목적은 중복된 데이터를 업데이트(갱신)하면서 생기는 관련된 모든 문제를 피하는것을 의미한다.
# 정규화의 과정
| 제 1정규화 ➡️ 제 2정규화 ➡️ 제 3정규화 ➡️ Boyce-Codd 정규화 ➡️ 제 4정규화 ➡️ 제 5정규화 |
즉, 제 3정규화를 할려면 제2 정규화를 선행해야한다. "나 제 4정규화만 할래"가 안되고 다 선행으로 해야한다는 것이다.(보통은 제3 정규화까지만 하는데 Boyce-Codd 정규화까지 포스팅을 할 예정이다)
# 제 1정규화(1NF)
"원자성" , 1NF의 핵심 키워드이다.
1NF의 Requirment는 아래와 같다.
- 각 테이블에서 중복을 제거한다.
- 관계된 데이터를 위하여 테이블을 분리한다.
- 관계된 데이터를 기본키로 식별한다.
원자성은 무엇을 의미하는걸까? 원자는 세상에서 쪼갤수 없는 단위를 이야기한다. 즉 제 1정규화에서는 쪼갤수 없을 때가지 테이블을 분리하라고 이야기하는 것이다.
<Normalization을 하지 않은 경우>
| 이름 | 과목 | 성적 |
| 철수 | 영어, 수학 | 90,78 |
| 영희 | 영어 | 90 |
<1NF>
| 이름 | 과목 | 성적 |
| 철수 | 영어 | 90 |
| 철수 | 수학 | 78 |
| 영희 | 영어 | 90 |
https://ko.wikipedia.org/wiki/%EC%A0%9C1%EC%A0%95%EA%B7%9C%ED%98%95
제1정규형 - 위키백과, 우리 모두의 백과사전
위키백과, 우리 모두의 백과사전. 제1정규형(1NF 또는 최소형)은 데이터베이스 정규화에서 사용하는 정규형중 하나이다. 관계형 데이터베이스의 테이블이 1NF이면 최소한 테이블은 관계[1]이며,
ko.wikipedia.org
# 제 2정규화(2NF)
"부분 함수적 종속 관계의 분리"
제 2정규화는 PK가 여러 키로 구성된 복합키로 구성된 경우가 제2정규화의 대상이된다. 즉, 기본키가 아닌 모든 속성이 기본키에 완전 함수 종속이 되면 제2정규형에 속한다.
뭐 부분함수니 복합키니 이런 이야기를 하는 것보다 제 1정규화는 행 구분 즉, 튜플을 구분할 수 없다. 즉, 위쪽에 표에서 철수가 중복된 데이터이고 점수도 중복 데이터가 될 수도 있다는 말이다. 이는 돌려서 이야기 하면 점수만 알면 과목과 이름을 알 수도 있다는 말이다.

2NF는 기본키 중에 특정 컬럼에만 종속된 컬럼이 존재할 경우 제2정규화에 위배된다. 기본키인 이름, 과목이 종속된 컬럼으로 제2 정규화를 위배한다는 것이다.
# 제 3정규화(3NF)
"이행 함수적 종속 관계의 분리"
이행 함수적 종속 관계는 X ➡️Y, Y➡️Z 일때 X➡️Z를 만족을 의미한다.
상품코드와 대분류, 소분류의 테이블을 갖고 있다고 가정하자.
상품코드를 알면 대분류를 알 수 있고 대분류를 알면 소분류를 알 수 있다.
참 아이러니하게도 그런 테이블이라면 상품코드를 알면 소분류를 알 수 있다는 것이다.

제 3정규화는 이런 이행 함수적 종속관계를 분리한다.
상품코드를 알면 대분류를 알아도 소분류는 다른 분류 카테고리 라는 테이블을 만들어서 관리한다는 것이다.
정규화는 무조건 좋은 것만은 아니다. 정규화를 통해 테이블 분리를 하게되면 JOIN을 해서 데이터를 처리해야하는데 리소스를 많이 잡아먹는 항목중 하나이다. 정규화를 잘게 쪼개 두면 오히려 유지보수함에 불리할 수 가 있다.
다시 한번 기억하자. 정규화는 데이터의 무결성을 위해서 사용되는 기법이다.데이터의 유지보수성도 올릴 수있다.

'Computer Science > DataBase' 카테고리의 다른 글
| [DB] Key의 종류 (0) | 2024.02.21 |
|---|---|
| [DB] 데이터 모델과 용어정리 (0) | 2024.02.20 |
| [DB] DataBase와 SQL VS. NoSQL (0) | 2024.02.19 |